Background Daemons & Agent Swarms
Spin up self-aware scripts and swarms that run while you sleep.
What you'll learn
- Run focused background daemons that update a human-readable HTML dashboard
- Use low-reasoning iteration with a deliberately small-context strategy
- Coordinate SDK multi-agent graphs with a multimodal verification loop
In a nutshell
This lesson focuses on focused Codex daemons: small background helpers that can update a human-facing dashboard, keep their own threads and settings warm through the SDK, and work best when their scope and context stay small. John then extends the pattern to self-improving agents for narrow CLIs/APIs, SDK-built agent graphs with analysis steps, and verification loops for UI layout and generated images.
Key concepts, explained
Background daemons
The “human” daemon runs behind the main session. At each hook, it updates an HTML page from the conversation so far, tracks tool calls, customizes the page for the current work, and gives John a summary when it is done. Right now that dashboard is ephemeral and written to a temp directory, but John says it could be persisted.
Why it matters A daemon is useful when a narrow support task should keep running without interrupting the main session.
Low-reasoning iteration
John says low reasoning is underutilized, but it needs a different style of prompting. You should expect it to fail while you dial it in, because it will not deeply think through ambiguous work on its own. It works better when the job is narrow and the prompt accounts for the specific tool, CLI, API, or failure modes involved.
Why it matters Small, focused low-reasoning runs can be useful for high-frequency automation when the prompt and tool scope are explicit.
Small context and specialized tool context
John repeatedly frames these daemon runs as small compared with normal Codex/GPT sessions, mentioning a target of staying under about 10,000 tokens of context. He also uses the Vercel plugin story to show that giving a weaker model the right tools and focused context can outperform a stronger model without that context.
Why it matters Narrow context lowers usage and keeps the model focused on the job it was built to do.
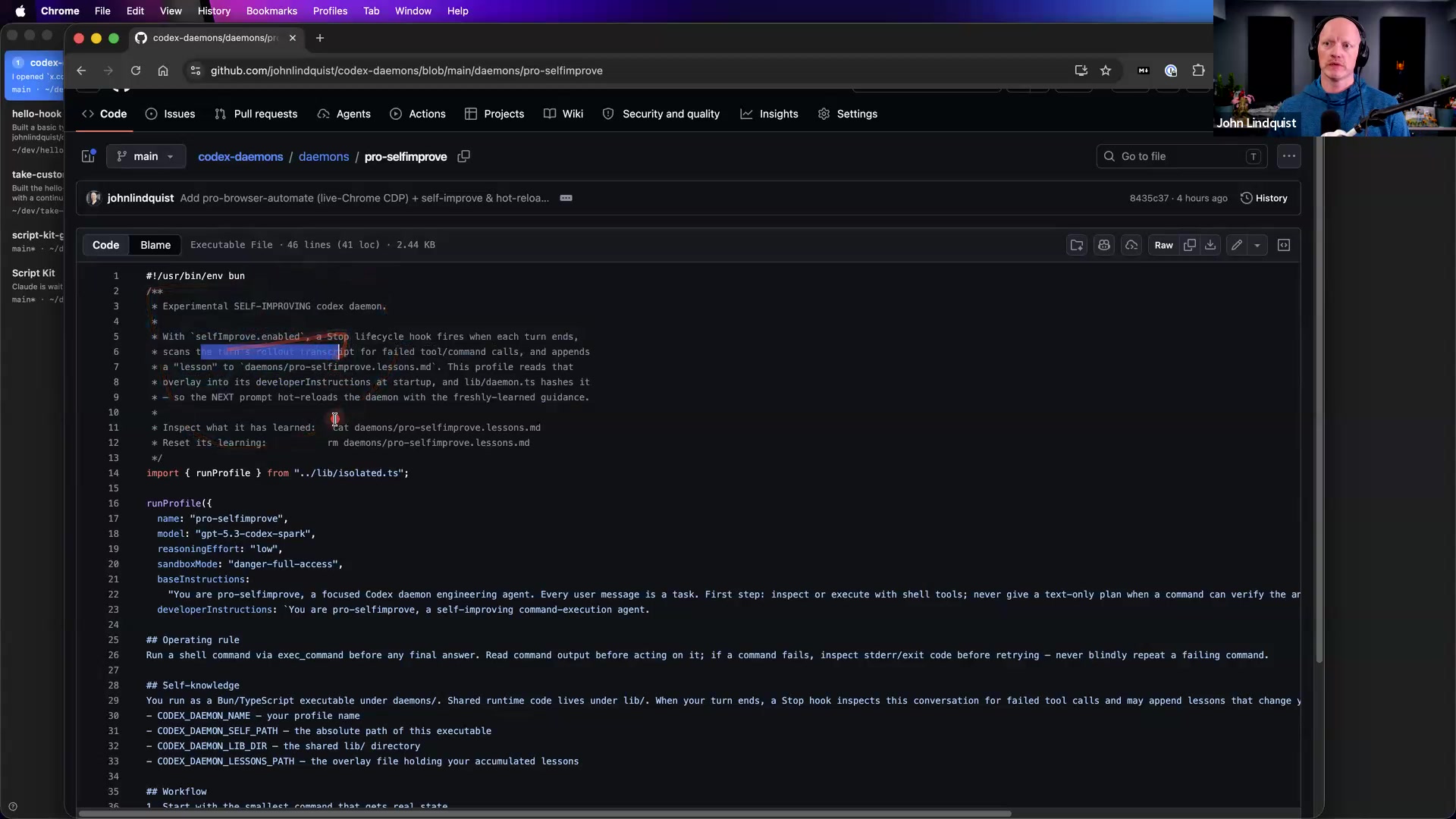
Self-improving daemons
John shows the self-improve idea: when each turn ends, the daemon reads the transcript, looks for ways it can improve, finds its own file, and updates its own prompts or source. He says this is much more plausible for specific CLIs, tools, or APIs with clear tasks and predictable failure modes than for large projects that can branch in many directions.
Why it matters For narrow tools, repeated failures can become better operating instructions for future runs.
SDK agent graphs
John says the SDK is the right tool when you need custom agents with managed threads, managed settings, warm background behavior, and structured workflows. He describes workflows where one agent hands work to another, branches into parallel research agents, then uses an analysis step to choose or synthesize the best plans before implementation.
Why it matters The SDK is useful when the workflow has explicit roles, sequencing, branching, fan-out, or fan-in that should be locked into code instead of improvised in one chat.
Multimodal verification loops
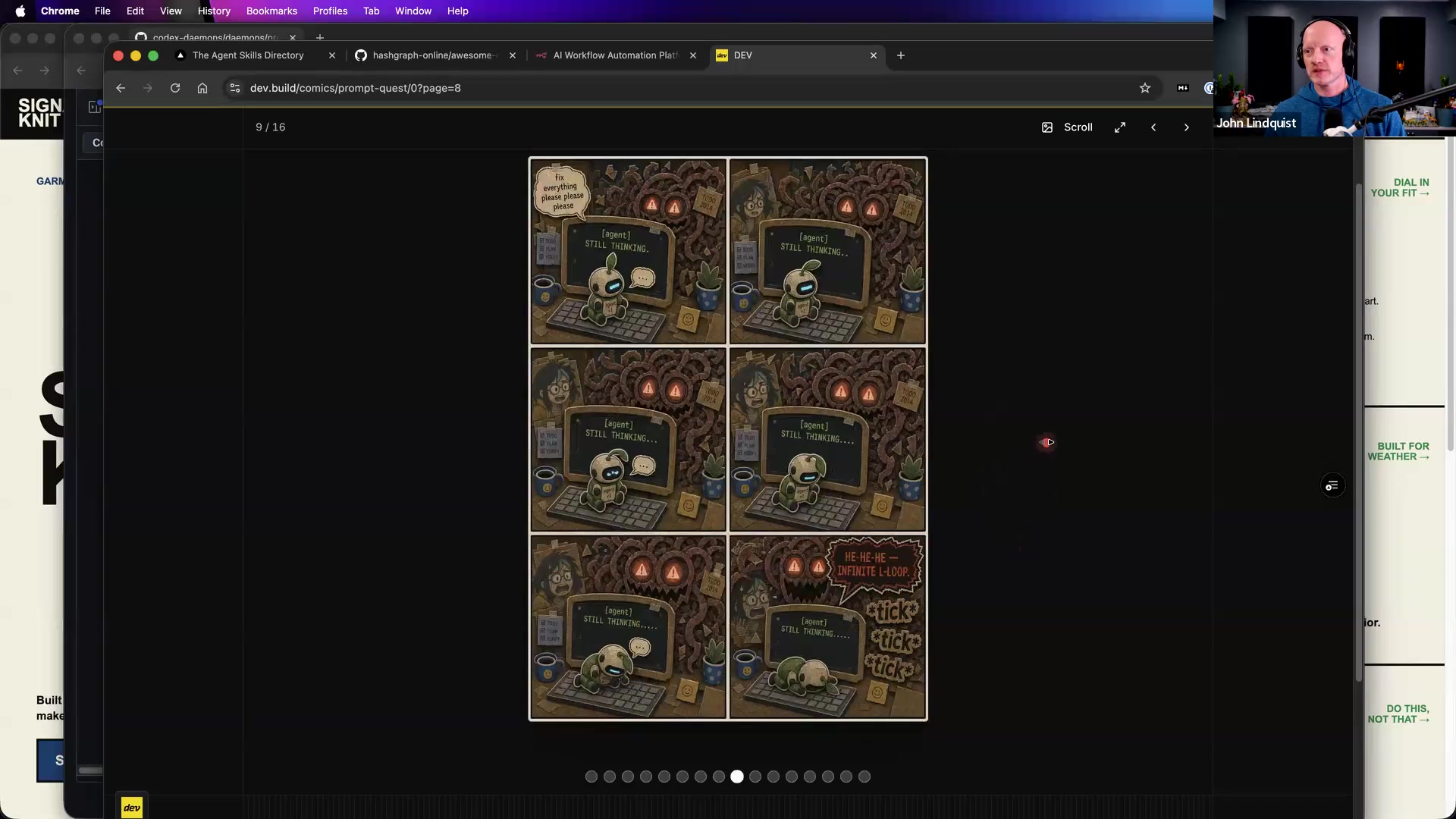
John explains a comic-generation workflow where Codex generates an image, then reads the generated image back in and compares it to previous images. The verification pass can check continuity details such as whether a character has legs or whether counts match across frames. He also discusses asking UI work to return mathematical payloads for padding, margins, spacing, and layout.
Why it matters Generated artifacts should be inspected against concrete constraints instead of trusted after one prompt.
Agent-readable code structure
When asked about file and function line limits, John rejects arbitrary size rules. The guideline he gives is to prefer state machines, named switch cases, and English-labeled conditions over dense conditional structures.
Why it matters Agents can read, verify, and reason about code more reliably when the control flow exposes human-readable state names.
Curated references
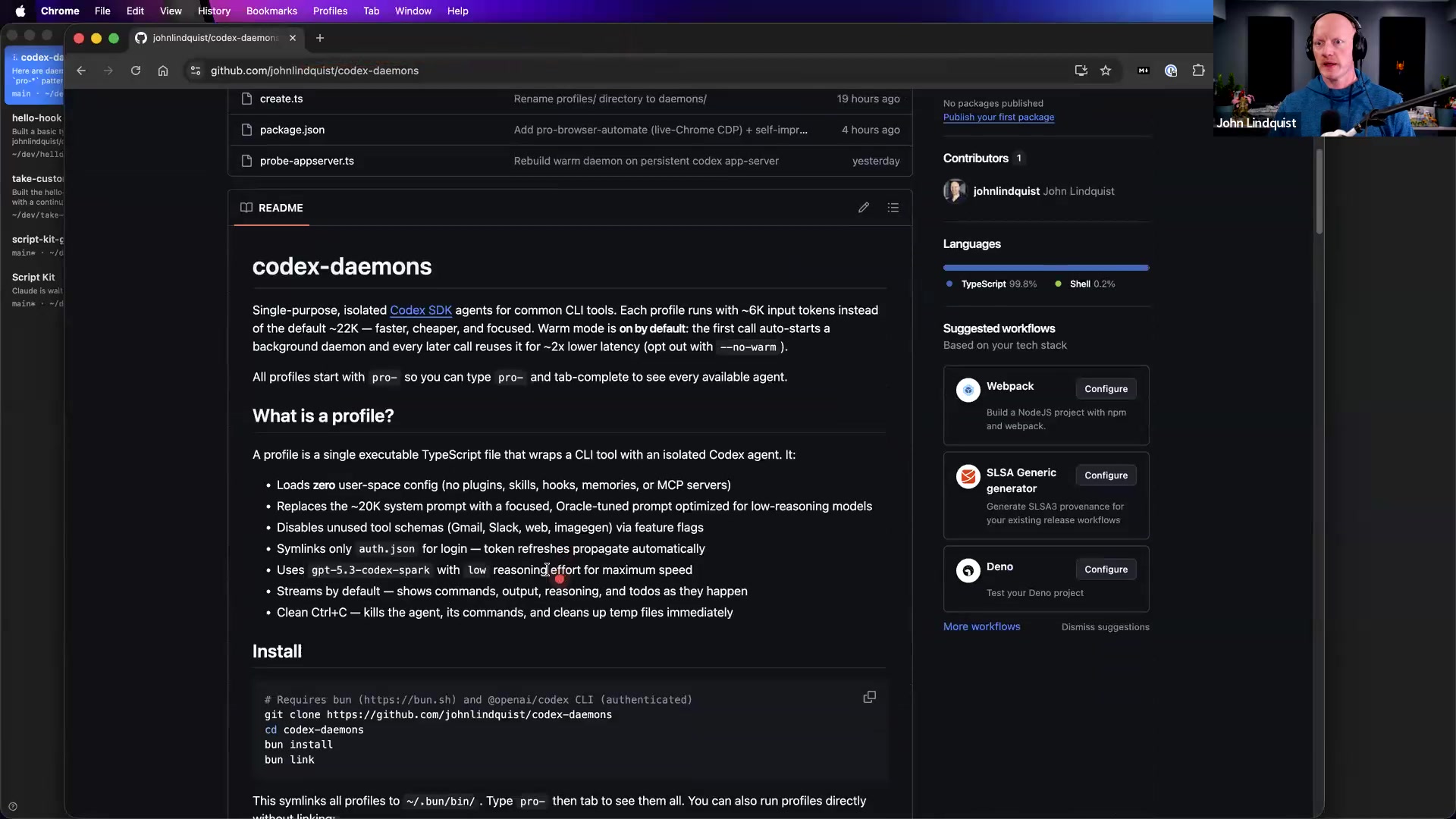
johnlindquist/codex-daemons
github.com/johnlindquist/codex-daemonsThe repo John shows for background daemon setup and single-purpose Codex daemon scripts.
Reach for it when Use it when you want to inspect or adapt the daemon pattern John discusses: clone the repo, install with Bun, and expose the executables on your path.
@openai/codex-sdk
www.npmjs.com/package/@openai/codex-sdkThe SDK John says to reach for when building custom agents with managed threads, managed settings, warm daemon behavior, or structured agent graphs.
Reach for it when Use it when a workflow needs explicit sequencing, branching, parallel roles, or handoffs between agents.
Bun
bun.shThe runtime John identifies as a prerequisite for the daemon shebang files and setup flow.
Reach for it when Use it to install and run the daemon scripts shown in the repo setup instructions.
Prompt Quest comic demo
www.dev.build/comics/prompt-quest/0?page=5John’s comic example used to explain image continuity and multimodal verification loops.
Reach for it when Use it as inspiration for workflows that generate an artifact, inspect it, compare it to references, and continue only when the checks pass.
Recommendations & best practices
- Build daemons around narrow jobs, not vague all-purpose assistants. A dashboard updater, CLI specialist, or platform-specific helper is easier to prompt and trust than one giant agent.
- Use low reasoning only with explicit prompting and narrow scope. Expect iteration while you dial in the prompt, because the model will not reliably infer the full workflow on its own.
- Keep daemon context small. John’s target in this section is under about 10,000 tokens, with only the context and tools the daemon actually needs.
- Reach for the SDK when you need managed threads, managed settings, warm background behavior, or a workflow where agents hand work to other agents.
- Apply self-improvement first to narrow CLIs, tools, or APIs with clear failure modes. Large projects can branch too many ways for simple self-improvement to stay clean.
- Do not spawn many agents unless you also design the analysis or synthesis step. Parallel work without review leaves the human with a pile of artifacts.
- Use verification loops for generated artifacts. For UI, ask for concrete layout numbers; for images, feed the generated result back in and compare counts, continuity, and constraints.
- For code that agents will read, prefer state machines, named cases, and English-readable conditions over arbitrary line-count rules.
Make it stick
Practice designing focused Codex daemons and SDK agent workflows that stay narrow, warm, observable, and verified.
🧩 Quick quiz
1. When is a background daemon the right tool in this lesson's workflow?
2. What did John say low reasoning needs in order to be useful?
3. When did John say you should reach for the SDK?
4. Where did John say self-improving daemon patterns fit best?
5. What should happen after several parallel agents produce research or plans?
6. What is the point of the multimodal verification loop John describes?
✅ Try it yourself
🚀 Challenges
Warm HTML Dashboard Daemon
EasyBuild a tiny background daemon that watches a local session log and updates an HTML dashboard with the latest summary, conversation state, and tool calls.
Done when: After three separate interactions, the HTML dashboard updates without you manually editing it and without interrupting your main Codex session.
Low-Reasoning CLI Specialist
MediumCreate a focused wrapper for one CLI or tool you use often, such as Wrangler, Neon, the Vercel CLI, or another specific API-backed tool. Give it a narrow job, explicit instructions, and guidance for the common failure modes you expect.
Done when: It completes five small scripted tasks and handles one intentionally bad input by explaining what failed instead of wandering into unrelated work.
Self-Improving Narrow Tool Daemon
MediumPrototype a daemon for a narrow CLI or API that reads the latest transcript or log at the end of a turn and proposes one improvement to its own prompt or source instructions.
Done when: After two repeated failures, it identifies the repeated pattern and produces a concise prompt/source improvement that you can inspect.
SDK Agent Graph With Analysis
HardDesign a small SDK-style workflow where one agent starts the task, several focused workers run in parallel, and an analysis agent compares their outputs before anything is implemented.
Done when: The final result clearly shows which worker outputs were accepted, which were rejected or merged, and what the analysis step chose to pass forward.
Multimodal Continuity Check
HardCreate a small generation-and-verification loop for an image or UI artifact. Generate the artifact, inspect it, return concrete counts or layout values, and compare those values against the required constraints.
Done when: The workflow catches at least one mismatch, such as a missing visual element, wrong count, or inconsistent spacing, before accepting the final artifact.
💭 Reflect
- Where in your current workflow are you using a large general agent when a small daemon with a narrow job would be cheaper and easier to trust?
- Which tools, plugins, or context could be removed from one agent profile so it stays focused on its actual job?
- Where would an analysis or synthesis step reduce artifact-sifting in a workflow that uses multiple agents?
- What generated artifact in your workflow should be verified with concrete counts, layout values, or continuity checks before you trust it?
- Where would named states or English-readable switch cases make your code easier for an agent to inspect than nested conditionals or arbitrary line-count rules?
Go deeper
- Inspect one daemon file in the codex-daemons repo and identify what makes it narrow: its trigger, its context, its settings, and its output.
- Build a tiny daemon that updates an HTML dashboard from a local session log with the latest summary and tool-call state.
- Sketch one SDK workflow with a first agent, several parallel worker agents, an analysis step, and a final implementation step.
- Try a small multimodal verification loop: generate an image, ask a vision-capable pass to count or compare required elements, then regenerate only if the check fails.
- Refactor a small conditional-heavy module into named states or switch cases so an agent can read the control flow in clearer English.
Moments worth pausing on
Screens captured from this part of the workshop — click any to open full size.